In the era of artificial intelligence and machine learning, chatbots have gained a lot of attention. Chatbots can for example help a user to book restaurants or schedule flights. But why should organizations use chatbots instead of simple user interaction (UI) systems? Considering that chatbots are both easier and more natural to interact with -compared to that of a UI system – endorses the implementation of chatbots in certain use cases. Additionally, a chatbot can engage a user for a longer time which can result in a company increasing its business. A chatbot needs to understand the natural language as there can be multiple ways to express one’s intention with language ambiguity. Natural Language Processing (NLP) helps us to achieve this to some extent.
Natural language processing – the foundation for a chatbot
Compared to rule-based solutions, chatbots using machine learning and language understanding are much more efficient. After years and new waves of statistical models, such as deep learning RNN, LSTM, transformers etc., these algorithms have now become market standards.
NLP is a part of linguistics and artificial intelligence, where algorithms are used to understand, analyze, manipulate and potentially generate human readable text. Usually, it contains two components: Natural Language Understanding (NLU) and Natural Language Generation (NLG).
To start with, the natural language input is mapped into useful representation for machine reading comprehension. This is achieved through using basics like: tokenization, stemming / lemmatization or tagging part of speech. There are also more advanced elements such as recognizing named entities or chunking. The latter is a processing method which organizes the individual terms found previously into a more prominent structure. For example: ’South Africa’ – is more useful as a chunk than the individual words ‘South’ and ‘Africa’.
FIGURE 1: A PROCESS OF BREAKING A USER’S MESSAGE INTO TOKENS
From the other side, NLG is the process of producing meaningful phrases and sentences in natural language from an internal structural representation using e.g. content determination, discourse planning, sentence aggregation, lexicalization, referring expression generation or linguistic realization.
Open-domain and Goal-Driven Chatbot
Chatbots can be classified into two categories: Goal-driven and Open-domain. Goal-driven chatbots are built to solve specific problems such as a flight bookings or restaurant reservations. On the other hand, the Open-domain dialogue system attempts to establish a long-term connection with the user, such as psychological support and language learning.
Goal-driven chatbots are based on slot filling and handcrafted rules, which are reliable but restrictive in conversation. A user has to go through a predefined dialogue flow to accomplish a task.

FIGURE 2: ARCHITECTURE FOR GOAL-DRIVEN CHATBOT
Open domain chatbots are intended to converse coherently and engagingly with humans and maintain a long dialog flow with a user. However, we need to have big amounts of data to train these chatbots.

FIGURE 3: ARCHITECTURE FOR OPEN-DOMAIN CHATBOT
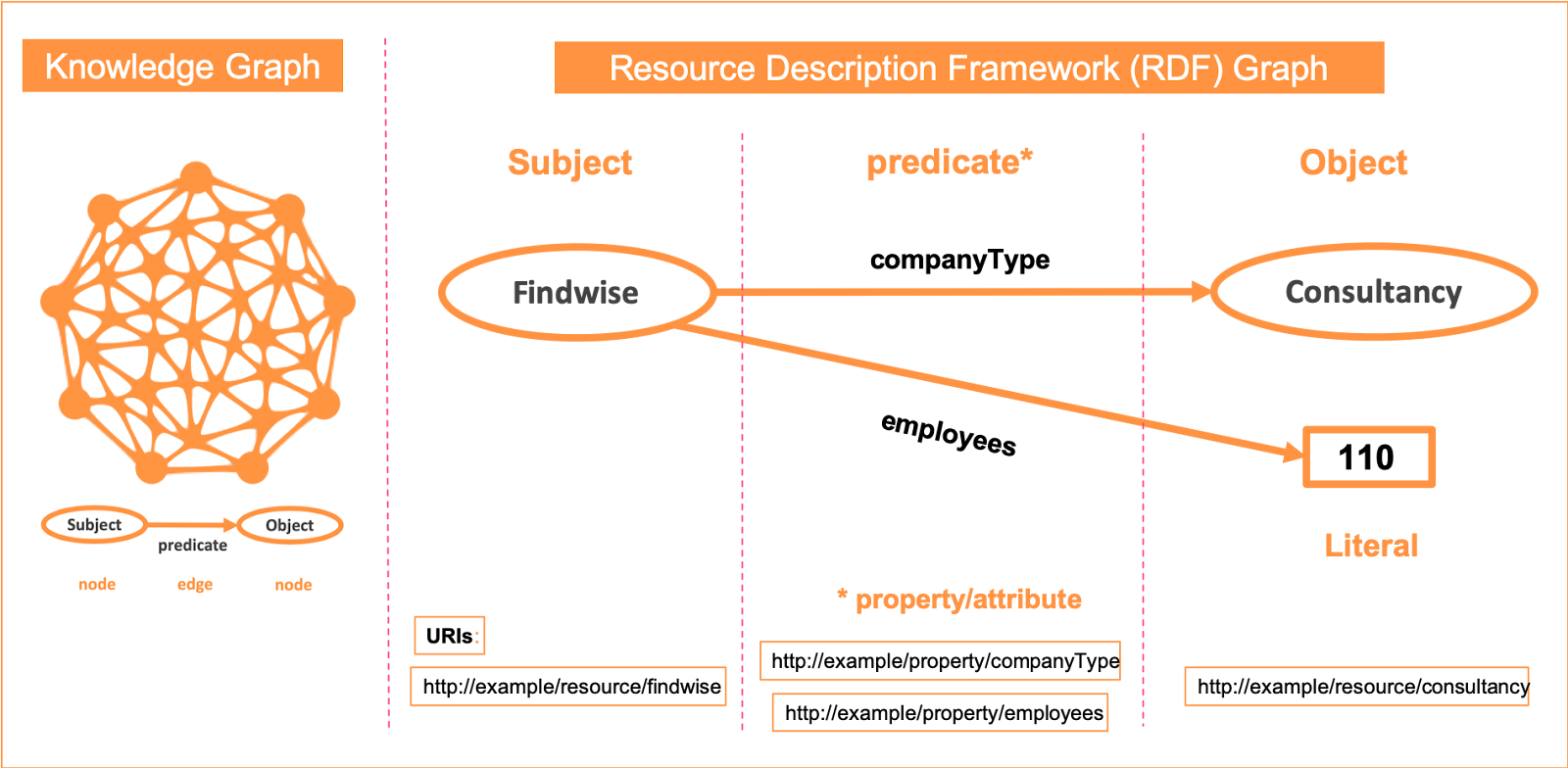
Knowledge graphs bring connections and data structures to information
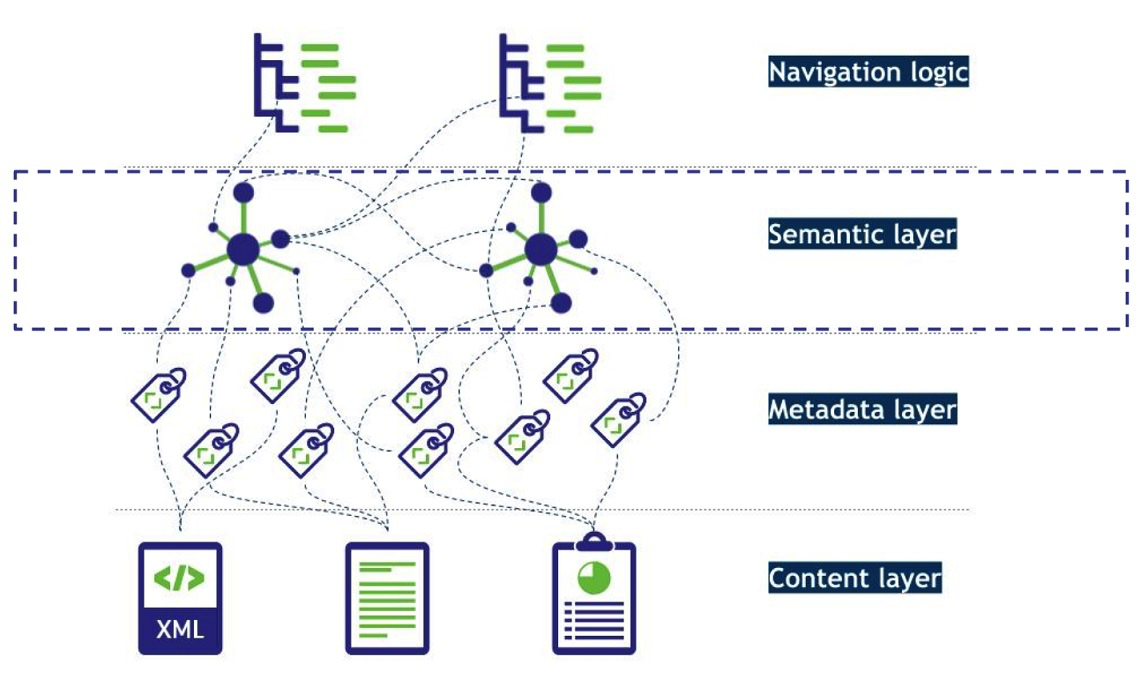
Knowledge graphs provides a semantic layer on the top of your database which provides you with all possible entities and the relationships between them. There are a number of representation and modeling instruments available for building a knowledge graph, ontologies being one of them.
Ontology comprises of classes, relationships and attributes as shown in Figure 9. This offers a robust way to store information and concepts – similar to how humans store information.

FIGURE 4: OVERVIEW OF A KNOWLEDGE GRAPH WITH AN RDF SCHEMA
A chatbot based on ontology can help to clarify the user’s context and intent – and it can dynamically suggest related topics. Knowledge graphs represent the knowledge of an organization, as depicted in the following Figure 10. Consider a knowledge graph based on an organization (as shown on the right image in Figure 10) and a chatbot (as shown on the left image in Figure 10) which is based on the ontology of this knowledge graph. In the chatbot example in Figure 10, the user asks a question about a specific employee. The NLP detects the employee as an entity and also detects the intent behind asking a question about this entity. The chatbot matches the employee entity in the ontology and navigates to the node in the graph. From that node we now know all possible relationships of that entity and the chatbot will ask back for possible options, such as co-workers and projects, to navigate further.

FIGURE 5: A SCENARIO – HOW A CHATBOT CAN INTERACT WITH A USER WITH A KNOWLEDGE GRAPH.
Moreover, the knowledge graph also improves the NLU in a chatbot. For example, if a user asks the following;
- ‘Which assignments was employee A part of?’. To navigate further in the knowledge graph, a rank system can be created for possible connections from the employee node. This rank system might be based on word vector space and a similarity score.
- In this scenario, ‘worked in, projects’ will have the highest rank when calculating the score with ‘part of, assignments’. So, the chatbot would know it needs to return the list of corresponding projects.
Virtual assistants with Lucidworks Fusion
Lucidworks Fusion is an example of a platform that supports building conversation interfaces. Fusion includes NLP features to understand the meaning of content and user intent. In the end, it’s all about retrieving the right answer at the right time. Virtual assistants, with a more human level of understanding, goes beyond static rules and profiles. It uses machine learning to predict user intention and provides insights. Customers and employees can locate critical insights to help them move to their next best action.

FIGURE 6: LUCIDWORKS FUSION DATA FLOW
Lucidworks recently announced Smart Answers – new Fusion’s feature. Smart Answers enhances the intelligence of chatbots and virtual assistants by using deep learning to understand natural language questions. It uses deep learning models and mathematical logic to match the similarity of a question (which can be asked in many different ways) to the most relevant answer. As users interact with the system, Smart Answers continues to rank all answers and improve relevancy.
Fusion is focused on understanding a user’s intent. Smart Answers includes model training and serving methods for different scenarios:
- When FAQs or question-answer pairs exist, they can be easily integrated into Smart Answers’ model training framework,
- When there are no FAQ or question-answer pairs, knowledge base documents can be used to train deep learning models and match existing knowledge for the best answers to incoming queries. Once users click on documents returned for specific queries, they become question-answers pairs signals and can enrich the FAQ model training framework,
- When there are no documents internally, Smart Answers uses cold-start models trained on large online sources, available in multiple languages. Once it goes live, the models begin training on actual user signals.
Smart Answers’ API enables easy integration with any platform, knowledge base, adding value to existing applications. One of the strengths of Fusion Smart Answers is integration with Rasa, an open-source conversation engine. It’s a framework that helps with understanding user intention and maintaining dialogue flow. It also has prebuilt NLP components such as word vectors, tokenizers, intent classifiers and entity extractor. Rasa allows to configure the pipeline that processes a user’s message and analyze human language. Another part of this engine enables modeling dialogues, so chatbot knows what the next action or response should be.
intent:greet - Hi - Hey - Hi bot - Hey bot ## intent:request_restaurant - im looking for a restaurant - can i get [swedish](cuisine) food in any area. - a restaurant that serves [caribbean](cuisine) food. - id like a restaurant - im looking for a restaurant that serves [mediterranean](cuisine) food - can i find a restaurant that serves [chinese](cuisine)
Building chatbots requires a lot of training examples for every intent and entity to make them understand the user intention, domain knowledge and to improve NLU of the chatbot. When building a simple chatbot, using prebuilt trained models can be useful and requires less training data. For example: If we build a chatbot where we only need to detect the common location entity, few examples and spaCy models can be enough. However, there might be cases when you need to build a chatbot for an organization where you need different contextual entities – which might not be available in the pretrained models. Knowledge graphs can then be helpful to have a domain knowledge for a chatbot and can balance the amount of work related to training data.
Conclusion
Two main chatbot usages are: 1/solving employee frustration in accessing e.g. corporate information and 2/providing customers with answers to support questions. Both examples above are looking for a solution to reduce time spent on finding information. Especially for online commerce, key performance indicators are clear and can relate to e.g. decreasing call center traffic or call deflection from web and email – examples of situations where ontology based chatbots can be very helpful. From a short-term perspective creating a knowledge graph can initially require a lot of effort – but from a long-term perspective it can also create a lot of value. Companies rely on digital portals to provide information to users; employees search for HR or organization policies documents. Online retailers try to increase customers’ self-service in solving their problems or simply want to improve discovery of their products and services. With solutions like e.g. Fusion Smart Answers, we are able to cut down time-to-resolution, increase customer retention and take knowledge sharing to the next level. It helps employees and customers resolve issues more quickly and empowers users to find the right answer immediately without seeking out additional, digital channels.
Authors: Pragya Singh, Pedro Custodio, Tomasz Sobczak
To read more:
- Ehud Reiter and Robert Dale. 1997. Building applied natural language generation systems. Nat. Lang. Eng. 3, 1 (March 1997), 57–87. DOI:https://doi.org/10.1017/S1351324997001502.
- Challenges in Building Intelligent Open-domain Dialog Systems by Huang, M.; Zhu, X.; Gao, J.
- A Novel Approach for Ontology-Driven Information Retrieving Chatbot for Fashion Brands by Aisha Nazir, Muhammad Yaseen Khan, Tafseer Ahmed, Syed Imran Jami, Shaukat Wasi
- https://medium.com/@BhashkarKunal/conversational-ai-chatbot-using-rasa-nlu-rasa-core-how-dialogue-handling-with-rasa-core-can-use-331e7024f733
- https://lucidworks.com/products/smart-answers/