In the last blog posts [1, 2] in this series by Fredric Landqvist and Peter Voisey we have outlined for you, at a high level, about the benefits of making data smarter and F.A.I.R., ideally made findable through a shareable, but controlled, type of Information Commons. In this post, we introduce you to Knowledge Graphs (based on Semantic Web Technologies), the source for the magic of smart and FAIR data automation. Data that is findable, accessible, interoperable and reusable. They can help tackle a range of problems, from the data tsunami to the scarcity of (quality) data for that next AI project.
What is a Knowledge Graph?
There are several different types of graph and certainly many have been many attempted definitions of a Knowledge Graph. Here’s ours:
A Knowledge Graph is the structural representation of explicit knowledge for a domain, encoded in such a way that both humans and machines can read (process) it.
Ultimately, we are wanting to exploit data and their connections or relationships within the graph format in order to surface important and relevant data and information. Without these relationships, the understandings, the stories and the searches around our data tend to dry up fairly quickly. Our world is increasingly connected. So we hope, from an organisational perspective, you are asking: Why isn’t our data connected?!
Where does the term “Knowledge Graph” come from?
The term Knowledge Graph was coined by Google on the release of its own Knowledge Graph in 2012. More recently, organisations have been cottoning on to the collective benefits of employing a Knowledge Graph, so much so, that many refer to the Enterprise Knowledge Graph today.
What are the technologies behind the Enterprise Knowledge Graph?
The Enterprise Knowledge Graph is based on a stack of W3C-ratified Semantic Web Technologies. As their name alludes to, they form the basis of the Semantic Web. Their formulation began in 2001 with Sir Tim Berners-Lee. Sir Tim, not content with giving us the World Wide Web for free, pictured a web of connected data and concepts, besides the web of linked documents, so that machines would be able to understand our requests by virtue of known connections and relationships.
Why Enterprise Knowledge Graphs now?
These technologies are complex to the layperson and some of them are nearly 20 years old. What’s changed to make Enterprises take note of them now? Well worsening internal data management problems, the need for some knowledge input for most sustainable AI projects and the fact that Knowledge Graph building tools have improved to become collaborative and more user-friendly for the knowledge engineer, domain expert and business executive. The underlying technologies in new tools are more hidden from the end user’s perspective, allowing them to concentrate on encoding their knowledge so that it can be used across enterprise systems and applications. In essence, linking enterprise data.
Thanks to Google’s success in using their Knowledge Graph with their search, Enterprise Knowledge Graphs are becoming recognised as the difference between “googling” and using the sometimes-less-than-satisfying enterprise consumer-facing or intranet search.
The key takeaway here though is that real power of any knowledge graph is in its relationships/connections between concepts. We’ll look into this in more detail next.
RDF, at the heart of the Enterprise Knowledge Graphs (EKGs)
EKGs use the simple RDF graph data model at their base. RDF stands for Resource Description Framework – a framework for the way resources or things are described so that we can recognise more easily plus understand more about them.
An aside: We’re talking RDF (namespace) Knowledge Graphs here, rather than their sister graph type, Property Graphs, which we will cover in a future post. It is important to note that there are advantages with both types of graph and indeed new technologies are being developed, so processes can straddle both types.
The RDF graph data model describes a thing or a resource in terms of “triples”: Subject – predicate – Object. The diagram below illustrates this more clearly with an example.
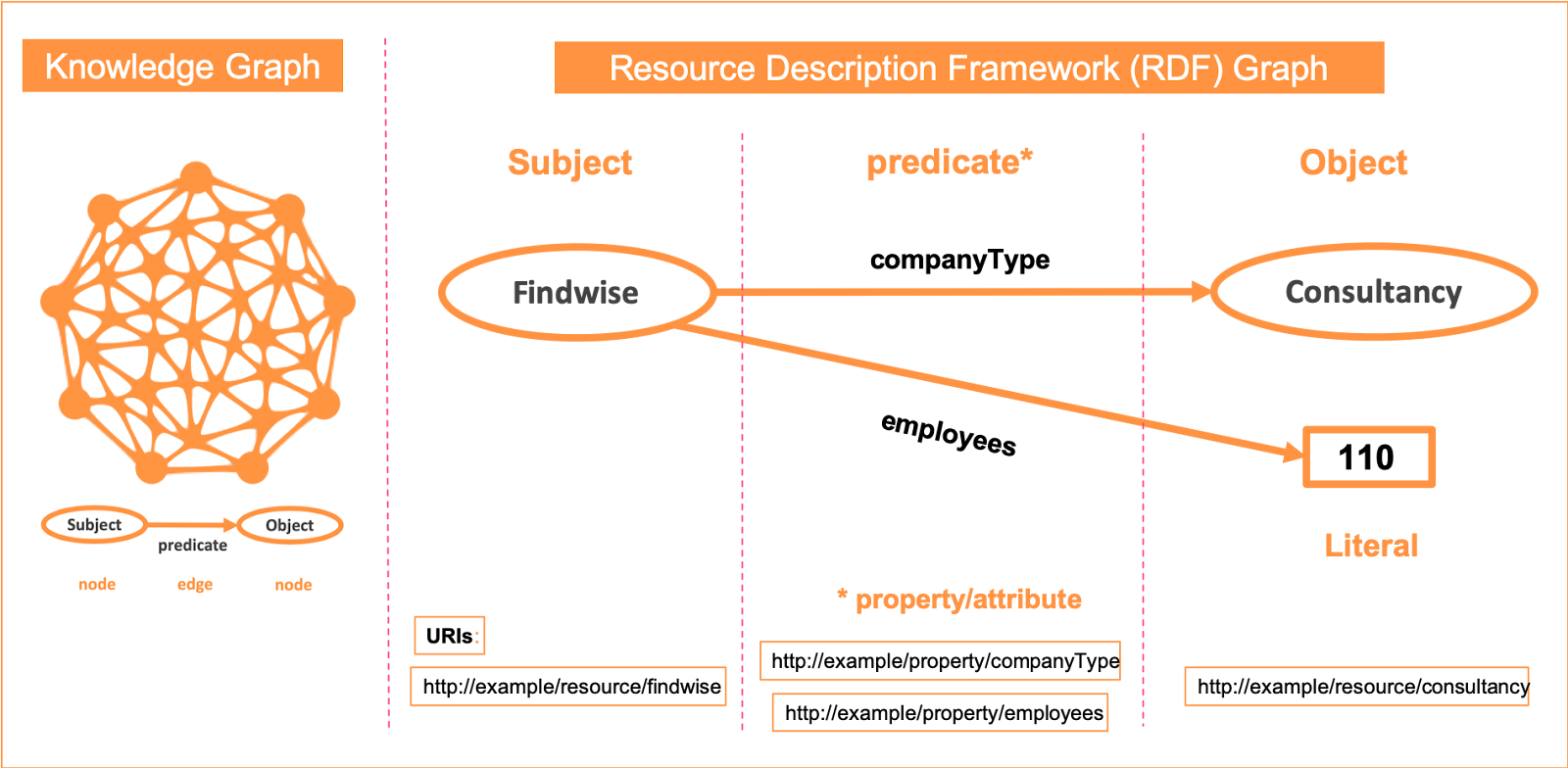
Figure 1. What does a Knowledge Graph look like? The RDF elements of a Knowledge Graph
The graph consists of nodes (vertices) that represent entities (a.k.a. concepts both concrete and abstract, terms, phrases, but now think things, not strings), and edges (lines or arrows) representing the relationships between nodes. Each concept and each relationship have their own URI (a kind of ID), that helps a search engine or application understand their meaning to spot differences (disambiguation) e.g. homonyms (words spelt or pronounced similarly, but that have different meaning) or similarities e.g. alternative labels, synonyms, acronyms, misspellings, foreign language term equivalents etc.
Google uses its Knowledge Graph when it crawls websites to recognise entities like: People, Places, Products, Organisations and more recently Topics, plus all their known relationships between them. There is often a dire need within most organisations for readily available knowledge about People and their related Roles, Skills/Competencies, Projects, Organisations/Departments and Locations.
There are of course many other well-known Knowledge Graphs now including IBM’s Watson, Microsoft’s Academic Knowledge Graph, Amazon’s Cortex Knowledge Graph, the Bing Knowledge Graph etc.
One thing to note about Google is that the space devoted to their organic (non-paid for) search results has reduced dramatically over the last ten years. In place, they have used their Knowledge Graph to better understand the end user’s query and context. Information too is served automatically based on query concept relationships, either within an Information Panel or as commonly known Questions and Answers (Q&As). Your employees (as consumers) of course are at home with this intuitive, easy-click user experience. While Google’s supply of information has become sharper, so has its automatic assessment of all webpage content, relying increasingly on websites to provide it with semantic information e.g. declaring their “aboutness” by using schema.org or other microformats in their markup rather than relying on SEO keywords.
How does Knowledge Graph engineering differ from traditional KM/IM processes?
In reality, not that much. We still want the same governing principles that can give data good structure, metadata, context and meaning.
Constructing a Knowledge Graph can still be likened to the development of taxonomy or thesaurus with their concepts and an ontology (the relationships between concepts). Here the relationships include firstly: poly-hierarchical relationships (in terms of the taxonomy): a concept may have several broader concepts meaning that the concept itself (with its own URI) can appear in multiple times within a taxonomy. This polyhierarchy can be exploited later for example in both search filtering and website navigation.
Secondly, relationships can also be associative/relational with regards to meaning and context – your organisation’s own made +/or industry-adopted concepts and the key relationships that define your business, and even its goals, strategy and workflows.
A key difference though is the way in which you can think about your data and its organisation. It is no longer flat or 2-D, but rather think 3-D and 360-degree concept- or consumer-centric views to see how they connect to other concepts.
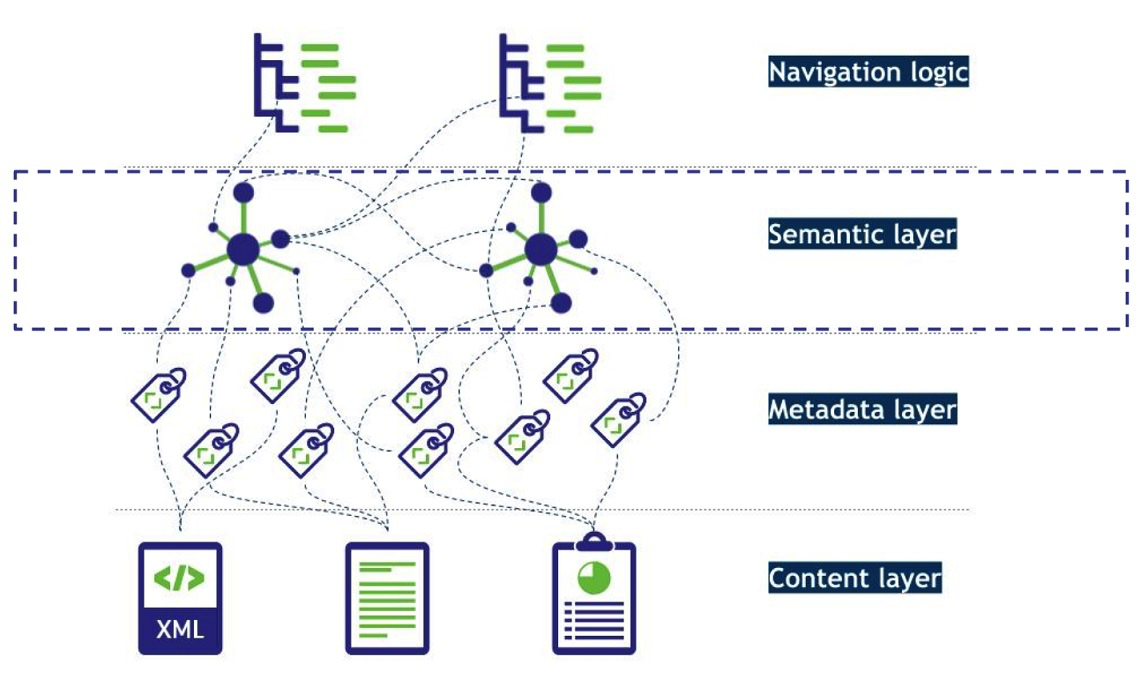
A semantic layer for Automatic Annotation, smarter data & semantic search
We will look at the many different benefits of a Knowledge Graph and further use cases in the next post, but for now, we go with the magic that an EKG can sit virtually on top of any or all your data sources (with different formats and metadata) without the need to move or copy any data. Any data source or data catalogue then consumed via a processing pipeline can be automatically and consistently be annotated (“tagged”) and classified according to declared industry or in-house standards, thus becoming more structured and its meaning more readily “understood,” ready to be found and consumed in accordance with any known or stated conditions.
The classification may also extend to including levels of data security and sensitivity, provenance or trust or location, device and time accessibility.
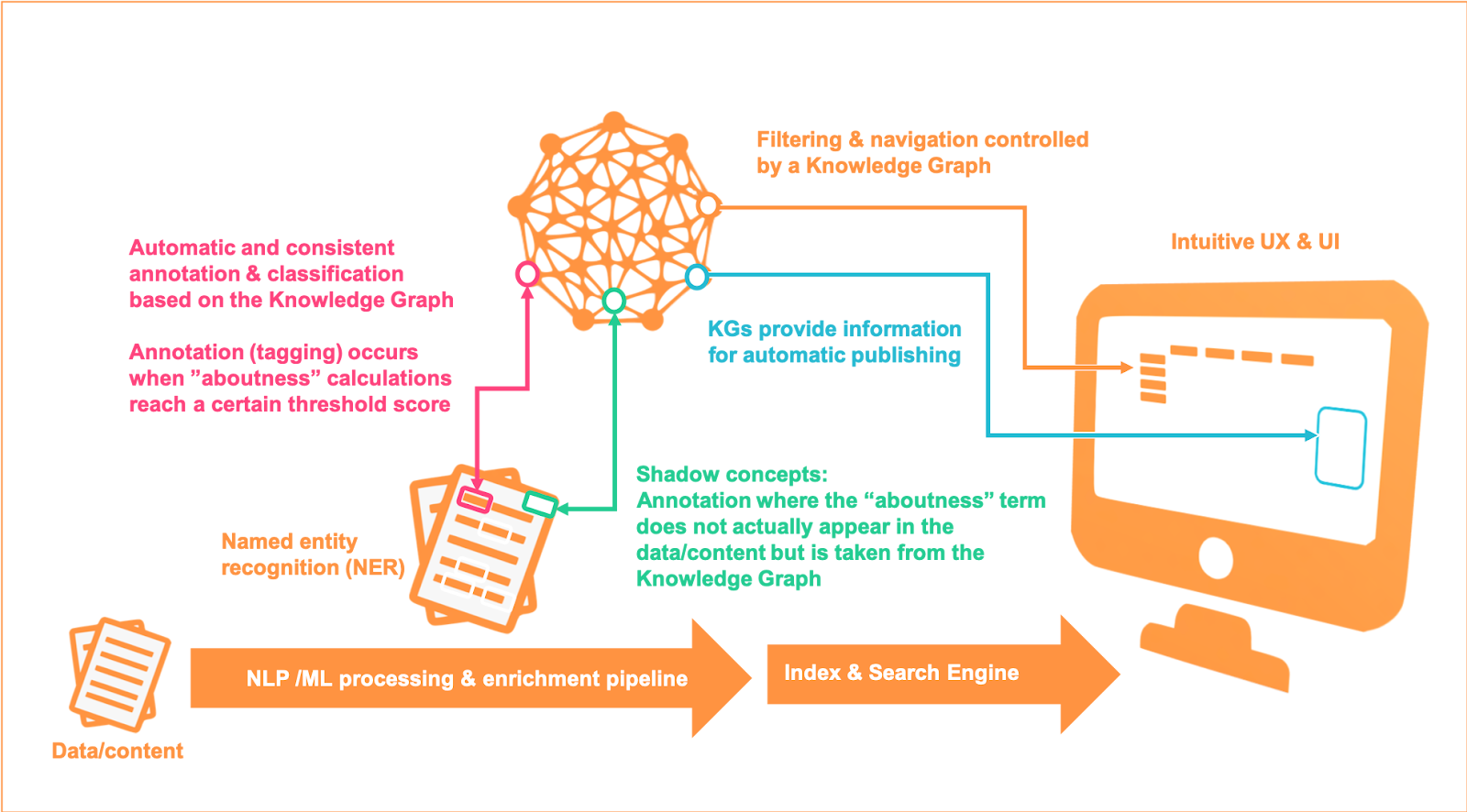
Figure 2 The automatic annotation & classification process for making data/content smart by using an Enterprise Knowledge Graph
It’s often assumed, incorrectly, that there is only one Enterprise Knowledge Graph. Essentially an enterprise can have one or many, perhaps overlapping graphs for different purposes, subject domains or applications. The importance is that knowledge becomes encoded and readily usable for humans and machines.
What’s wrong with Relational Databases?
There’s nothing wrong with relational databases per se and Knowledge Graphs will not necessarily replace them any time soon. It’s good to note though that data in tabular format can be converted to RDF graph data (triples/tuples) relatively easily and stored in a triple store (Graph Database) or some equivalent.
In relational databases, references to other rows and tables are indicated by referring to primary key attributes via foreign key columns. Joins are computed at query time by matching primary and foreign keys of all rows in the connected tables.
Understanding the connections or relations is usually very cumbersome, and those types of costly join operations are often addressed by denormalizing the data to reduce the number of joins necessary, therefore breaking the data integrity of a relational database.
The data models for relational versus graph are different. If you are used to modelling with relational databases, remember the ease and beauty of a well-designed, normalized entity-relationship diagram (i.e using UML) – a graph is exactly that – a clear model of the domain. Each node (entity or attribute) in the graph model directly and physically contains a list of relationship records that represent the relationships to other nodes. These relationship records are organized by type and direction and may hold additional attributes.
Querying relational databases is easy with SQL. The graph has something similar by using SPARQL, a query language for RDF. If you have ever tried to write a SQL statement with a large number of joins, you know that you quickly lose sight of what the query actually does. In SPARQL, the syntax remains concise and focused on domain components and the connections among them.
Toward data-centric solutions with RDF
With enterprise-linked-data, as with knowledge graphs, one is able to connect many different schemas (data models) and formats in different relational databases and build a connected worldview, domain of discourse. Herein lays the strengths with linking-data, and liberating data from lock-in mechanisms either by schemas (data models) or vendor (software). To do queries and inferencing to find new knowledge and insights that were not possible before due to time or human computation factors. Semantics support this reasoning!
Of course, having interoperable graph data means could well mean fewer code patches on individual systems and more sustainable and agile data-centric solutions in the future.
In conclusion
The expression “in the right place, at the right time” is generally associated with luck. We’ve been talking in our enterprises about “the right information, in the right place, at the right time” for ages, unfortunately sometimes with similar fortune attached. The opportunity is here now to embark on a journey to take back control of your data if you haven’t already, and make it an asset again in achieving your enterprise aims and goals.
More reading on graphs and linked enterprise data:
- Everything you need to know about graph technology and deep-learning
- Linking Enterprise Data, ed. David Wood 2011 (book)
Next up in the series: Knowledge Graphs: The collective Why?