I don’t want to sail with this ship of fools, on the opulent data sea, where people are drowning without any sense-making knowledge shores in sight. You don’t see the edge before you drop!
 Echoencephalogram (Lars Leksell) and neural networks
Echoencephalogram (Lars Leksell) and neural networks
How do organisations reach a level playing field, where it is possible to create a sustainable learning organisation [cybernetics]?
(Enacted Knowledge Management practices and processes)
Sadly, in many cases, we face the tragedy of the commons!
There is an urgent need to iron out the social dilemmas and focus on motivational solutions that strive for cooperation and collective action. Knowledge deciphered with the notion of intelligence and emerging utilities with AI as an assistant with us humans. We the peoples!
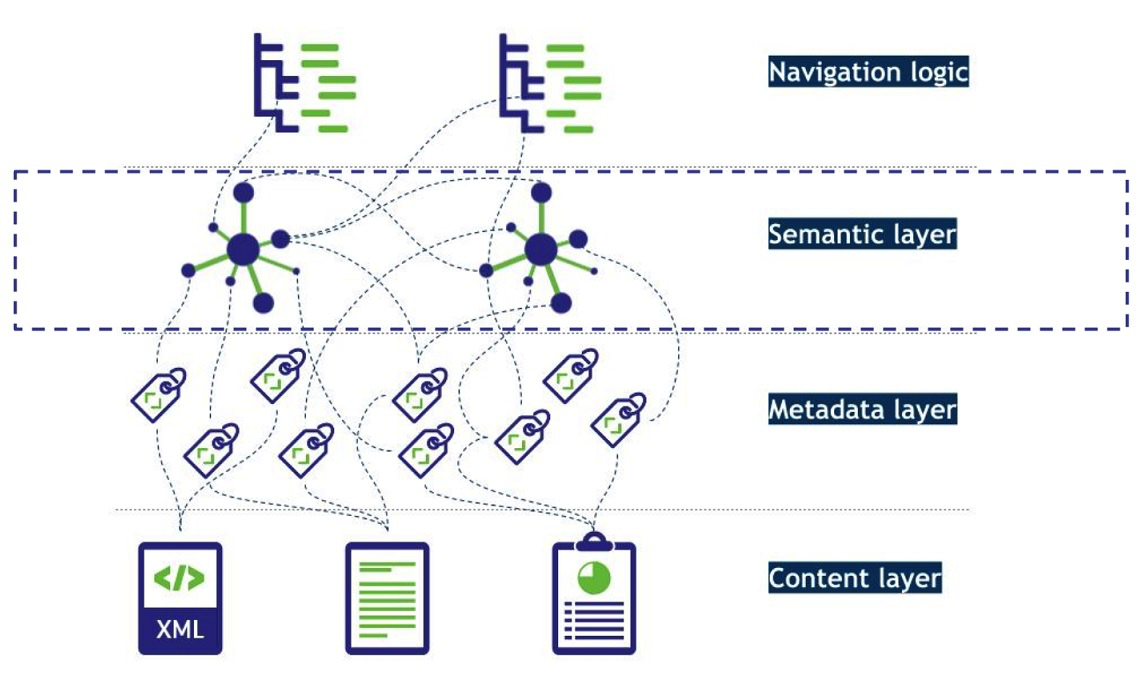
To make a model of the world, to codify our knowledge and enable worldviews to complex data is nothing new per se. A Knowlege Graph – is in its essence a constituted shared narrative within the collective imagination (i.e organisation). Where facts of things and their inherited relationships and constraints define the model to be used to master the matrix. These concepts and topics are our communication means to bridge between groups of people. Shared nomenclatures and vocabularies.

Knowledge Engineering in practice
At work – building a knowledge graph – there are some pillars, that the architecture rests upon. First and foremost is the language we use every day to undertake our practices within an organisation. The corpus of concepts, topics and things that revolve around the overarching theme. No entity act in a vacuum with no shared concepts. Humans coordinate work practices by shared narratives embedded into concepts and their translations from person to person. This communication might be using different means, like cuneiform (in ancient Babel) or digital tools of today. To curate, cultivate and nurture a good organisational vocabulary, we also need to develop practices and disciplines that to some extent renders similarities to ancient clay-tablet librarians. Organising principles, to the organising system (information system, applications). This discipline could be defined as taxonomists (taxonomy manager) or knowledge engineers. (or information architect)
Set the scope – no need to boil the ocean
All organisations, independent of business vertical, have known domain concepts that either are defined by standards, code systems or open vocabularies. A good idea will obviously be to first go foraging in the sea of terminologies, to link, re-hash/re-use and manage the domain. The second task in this scoping effort will be to audit and map the internal terrain of content corpora. Since information is scattered across a multitude of organising systems, but within these, there are pockets of a structure. Here we will find glossaries, controlled vocabularies, data-models and the like. The taxonomist will then together with subject matter experts arrange governance principles and engage in conversations on how the outer and inner loop of concepts link, and start to build domain-specific taxonomies. Preferable using the simple knowledge organisation system (SKOS) standard
Participatory Design from inception
Concepts and their resource description will need to be evaluated and semantically enhanced with several different worldviews from all practices and disciplines within the organisation. Concepts might have a different meaning. Meaning is subjective, demographic, socio-political, and complex. Meaning sometimes gets lost in translation (between different communities of practices).
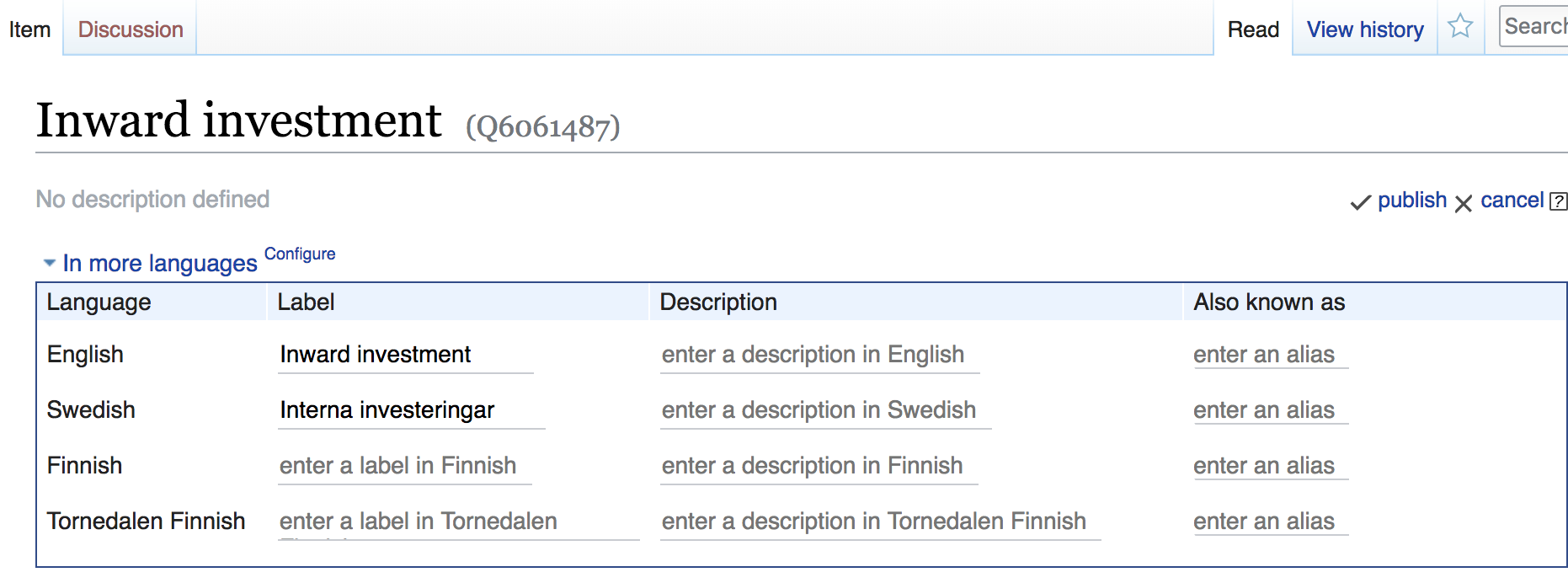
The best approach to get a highly participatory design in the development of a sustainable model is by simply publish the concepts as open thesauri. A great example is the HealthDirect thesaurus. This service becomes a canonical reference that people are able to search, navigate and annotate.
It is smart to let people edit and refine and comment (annotate) in the same manner as the Wikipedia evolves, i.e edit wiki data entries. These annotations will then feedback to the governance network of the terminologies.
Link to organising systems
All models (taxonomies, vocabularies, ontologies etc.) should be interlinked to the existing base of organising systems (information systems [IS]) or platforms. Most IS’s have schemas and in-built models and business rules to serve as applications for a specific use-case. This implies also the use of concepts to define and describe the data in metadata, as reference data tables or as user experience controls. In all these lego pieces within an IS or platform, there are opportunities to link these concepts to the shared narratives in the terminology service. Linked-enterprise-data building a web of meaning, and opening up for a more interoperable information landscape.
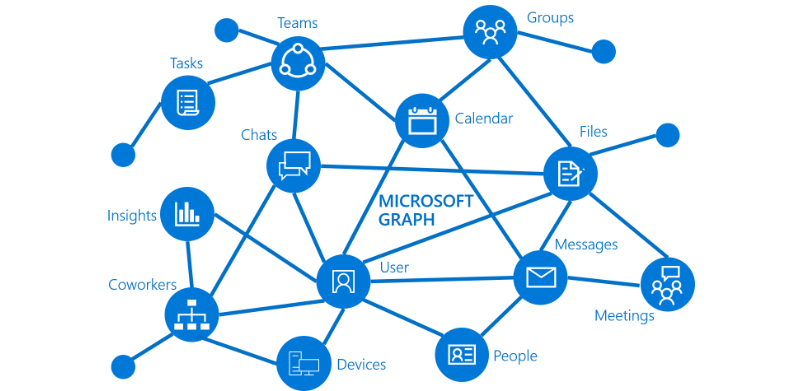
One omnipresent quest is to set-up a sound content model and design for i.e Office 365, where content types, collections, resource descriptions and metadata have to be concerted in the back-end services as managed-metadata-service. Within these features and capacities, it is wise to integrate with the semantic layer. (terminologies, and graphs). Other highly relevant integrations relate to search-as-a-service, where the semantic layer co-acts in the pipeline steps, add semantics, link, auto-classify and disambiguate with entity extraction. In the user experience journey, the semantic layer augments and connect things. Which is for instance how Microsoft Graph has been ingrained all through their platform. Search and semantics push the envelope 😉
Data integration and information mechanics
A decoupled information systems architecture using an enterprise service bus (messaging techniques) is by far the most used model. To enable a sustainable data integration, there is a need to have a data architecture and clear integration design. Adjacent to the data integration, are means for cleaning up data and harmonise data-sets into a cohesive matter, extract-load-transfer [etl]. Data Governance is essential! In this ballpark we also find cues to master data management. Data and information have fluid properties, and the flow has to be seamless and smooth.
When defining the message structure (asynchronous) in information exchange protocols and packages. It is highly desired to rely on standards, well-defined models (ontologies). As within the healthcare & life science domain using Hl7/FHIR. These standards have domain-models with entities, properties, relations and graphs. The data serialisation for data exchange might use XML or RDF (JSON-LD, Turtle etc.). The value-set (namespaces) for properties will be possible to link to SKOS vocabularies with terms.
Query the graph
Knowledge engineering is both setting the useful terminologies into action, but also load, refine and develop ontologies (information models, data models). There are many very useful open ontologies that could or should be used and refined by the taxonomists, i.e ISA2 Core Vocabularies, With data-sets stored in a graph (triplestore) there are many ways to query the graph to get results and insights (links). Either by using SPARQL (similar to SQL in schema-based systems), or combine this with SHACL (constraints) or via Restful APIs.
These means to query the knowledge graph will be one reasoning to add semantics to data integration as described above.
Adding smartness and we are all done…
Semantic AI or means to bridge between symbolic representation (semantics) and machine learning (ML), natural language processing (NLP), and deep-learning is where all thing come together.
In the works (knowledge engineering) to build the knowledge graph, and govern it, it taxes many manual steps as mapping models, standards and large corpora of terminologies. Here AI capacities enable automation and continuous improvements with learning networks. Understanding human capacities and intelligence, unpacking the neurosciences (as Lars Leksell) combined with neural-networks will be our road ahead with safe and sustainable uses of AI.
 Fredric Landqvist research blog
Fredric Landqvist research blog